今天服务挂了9小时
今天早上9点老大在群里发个截图,问我,这个服务怎么挂掉了,有没有加报警。吓得我立马穿上鞋子就往公司跑。因为这块是很关键的服务,订单、营收、佣金这都是电商的命脉,到公司之后发现,这个服务从昨晚0点开始就down掉了,然后到早上九点才发现和恢复。也就是整整挂掉了9个小时,这绝对是不可接受的。
然后,在这个过程中,还没有收到任何报警,毫无疑问,这全是我的问题,全责,虽然服务不是我弄挂的,但是告警策略制定的有问题,导致服务挂了9小时也没有收到告警,告警策略制定的缺陷源于对业务理解的还不够。当今天发现这个事实之后,真想找个洞钻进去,因为这是首页的关键服务,用户每次进来都会触发的服务,是绝对应该保证稳定性的。
后面到公司之后我查看了服务的监控图:
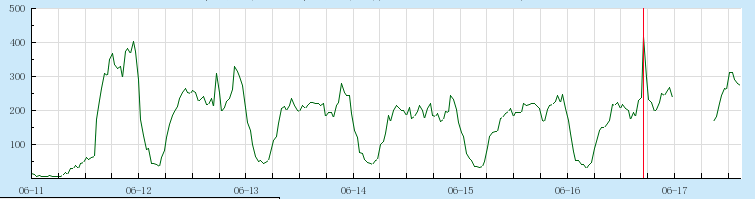
这个是以天为单位的监控图,从图中明显可以看到断了一截。然后我们把那个缺口细节放大看看另一张监控图:
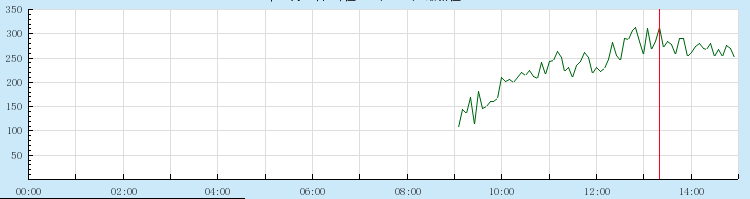
这个是以小时为单位的监控图,明确看到服务down了9小时。
来公司半年,就碰到了这个问题,还是在这么关键的时间点(因为明天就是京东6.18),惊动了上面N层的老大,留下的记忆太深,当然,也足足涨了一次经验值。
后面我又重新梳理了一下业务,更新了告警策略。把这个服务的子模块也全都加上了报警,顺便也把我以前写的几个模块加上了告警,虽然这次没问题,但顺着这次机会也就一起复查一下了。一般的告警大概三部分:
- 请求量的上限值:监控流量突增,防止恶意攻击,正常情况下考虑是否需要扩容;
- 请求量的下限值:监控服务是否down掉,如果请求量较低,很可能一部分服务已经down掉了,应该马上检查;
- 请求发生的错误数:监控服务的稳定性,这种情况主要是在自己服务中调用的其他业务的服务出了问题,影响到自己的服务,导致错误率上升。
写代码是一件很严肃的事!
2015.06.17 22:14